引言:
我要用dify连接gemini 因为他有免费api 额度,并且还算好用,没梯子不行。设置好了可以任意连接不多说了,操作吧
重要,你先要有个梯子,然后
1 进入dify/docker 目录
cd ./dify/docker
2 vi docker-compose.yaml
加入代理地址变量 ,把代理服务器换成自己的地址
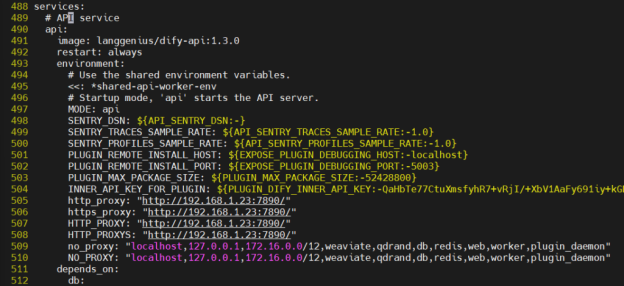
http_proxy: “http://192.168.1.23:7890/”
https_proxy: “http://192.168.1.23:7890/”
HTTP_PROXY: “http://192.168.1.23:7890/”
HTTP_PROXYS: “http://192.168.1.23:7890/”
no_proxy: “localhost,127.0.0.1,172.16.0.0/12,weaviate,qdrand,db,redis,web,worker,plugin_daemon”
NO_PROXY: “localhost,127.0.0.1,172.16.0.0/12,weaviate,qdrand,db,redis,web,worker,plugin_daemon”
有三台主机要加,
api主机
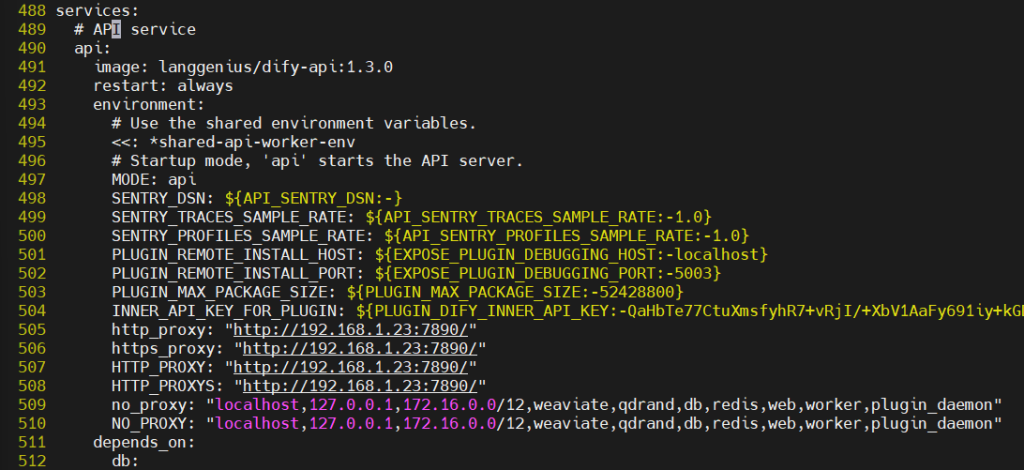
Sandbox 主机
注意:它原来有要注释掉
623 #HTTP_PROXY: ${SANDBOX_HTTP_PROXY:-http://ssrf_proxy:3128}
624 #HTTPS_PROXY: ${SANDBOX_HTTPS_PROXY:-http://ssrf_proxy:3128}
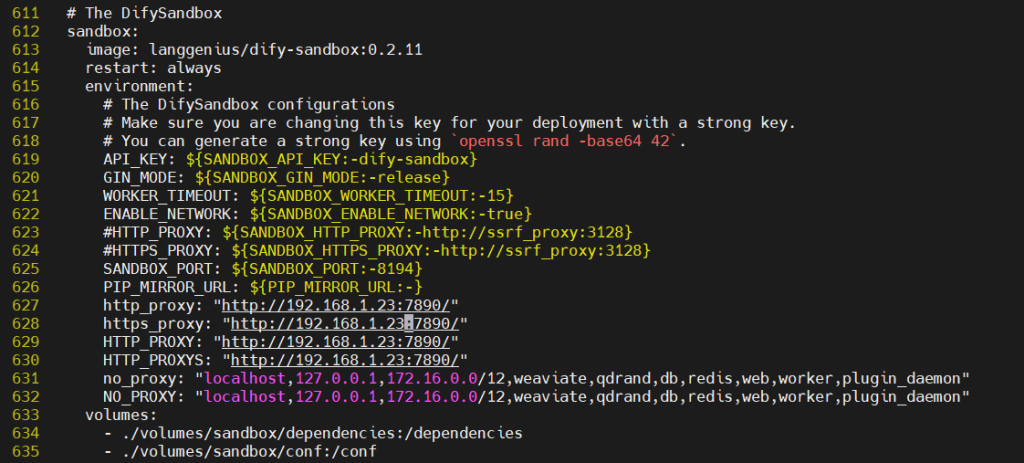
plugin_daemon主机
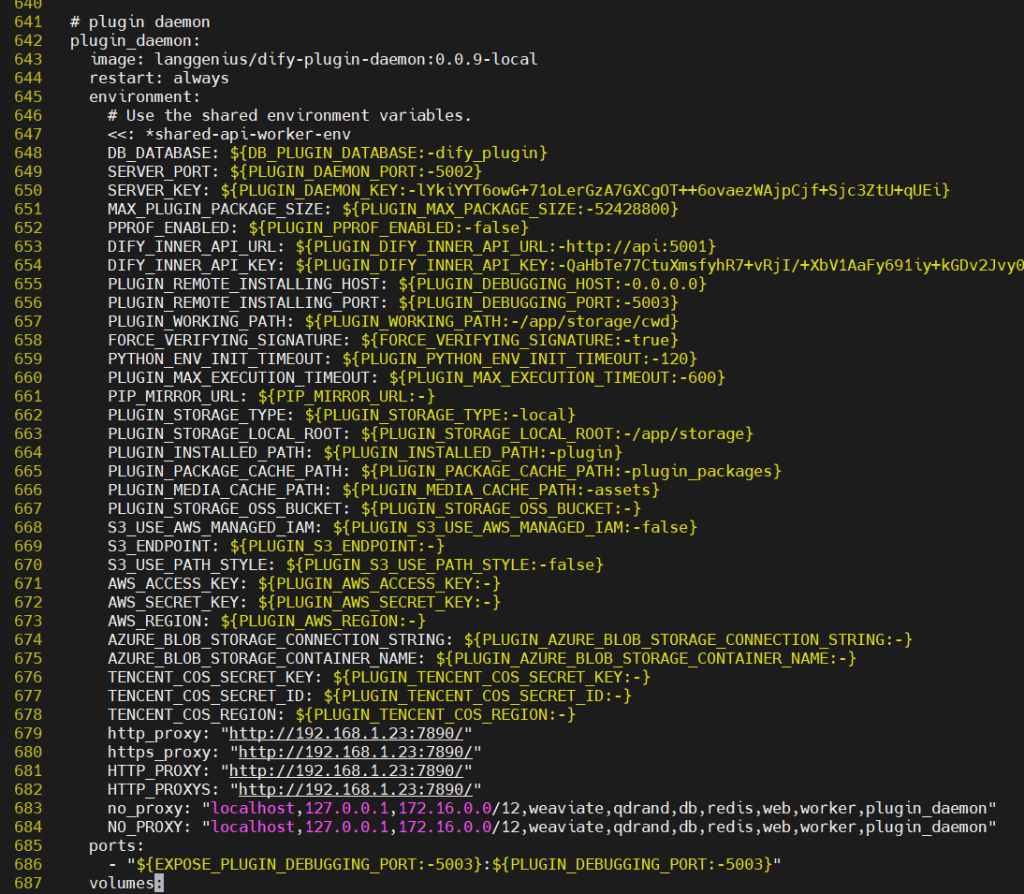
设置完了了
保存
:wq
然后重启服务
docker compose down
docker compose up -d
等一会儿
设置gemini api 成功了
OK了,bye
相关报错:expecting value:line1 column 1(char 0)